Tutorial_01
Tutorial
《Python3网络爬虫实战》(源码)
本书介绍了:网络爬虫的技术基础、Python常用IDE、数据存储、爬虫常用模块、Scrapy爬虫、BeautifulSoup爬虫、PyQuery模块、Selenium模块浏览器、PySpider框架图片验证识别、爬取APP、爬虫与反爬虫等。第3章 数据储存和解析
Python爬虫的原理:第一步:使用Python的网络模块(比如urllib2、httplib、requests等)模拟浏览器向服务器发送正常的HTTP(HTTPS)请求,服务器正常响应后,主机将收到包含所需信息的网页代码;
第二步:主机使用过滤模块(比如lxml、html.parser、re等)将所需信息从网页代码中过滤出来。
3.1 文件存储
读取文本文件内容,无需调用模块。
fp = open('test.txt', 'r') # 打开文件
content = fp.read() # 读取文件内容
print(content) # 输出内容
fp.close() # 关闭文件
写入文件
fp=open('test2.txt','w') #打开文件
content='''
苏幕遮•怀旧
范仲淹
碧云天,黄叶地,
秋色连波,波上寒烟翠。
山映斜阳天接水,芳草无情,
更在斜阳外。
黯乡魂,追旅思。
夜夜除非,好梦留人睡。
明月楼高休独倚,
酒入愁肠,化作相思泪。
''' #定义字符串
fp.write(content) #将内容写入文件
按行读取文件内容
fp=open('test.txt','r') #打开文件
list=fp.readlines() #将文件按行读取到列表
for l in list: #对列表进行遍历
print(l+"
") #输出内容
fp.close() #关闭文件
JSON文件存储:示例(3-4)-(3-7)
CSV文件存储:示例(3-8)-(3-12)
3.2 关系型数据库存储
本章的数据库是直接连接数据库文件:my_db.db,该文件可以使用SQLiteStudio打开。示例(3-13)-(3-18)。
3.3 非关系型数据库存储
本节介绍了非关系型数据库MongoDB的安装、操作。示例(3-19)-(3-30)。
3.4 lxml模块解析数据
示例(3-31)-(3-34)。
第4章 Python爬虫常用模块
4.1 技术核心。原理、策略、身份识别(cookie、session);
4.2 标准库urllib.request模块。直接抓取页面connBaidu.py、使用代理访问connWithProxy.py、修改header(浏览器userAgents.py、connModifyHeader.py)
4.3 标准库logging模块。日志模块,testLogging.py、自定义模块myLog.py
4.4 re模块(正则表达式)crawlWithRe.py
4.5 其它模块。sys模块(testSys.py)、time模块(testTime.py)、
第7章 PYQUERY模块
安装:pip install pyquery
抓取百度风云榜(7-11.py)、抓取微博热搜(7-12.py)
《Python应用实战 爬虫、文本分析与可视化》(中国工信出版集团 电子工业出版社 2020年)(源码 | 彩图)
教材分为5章。第1章为初识Python;第2章是网页;第3章是数据抓取;第4章是文本处理;第5章数据分析。
第1章 初识Python
该书推荐使用的IDE(集成开发环境,Integrated Development Environment)是Anaconda。而且还专门说明为什么不用PyCharm:Anaconda因包含了大量的科学包或模块更适合初学者。书中还介绍了使用Jupyter的方法:点击“Jupyter Notebook”图标,即可打开浏览器:http://localhost:8888/tree,点击网页右上角的New菜单,选择Python 3,即可进入Python命令行模式。并且点击上方的标题栏改名保存。
Jupyter使用的是ipynb(ipython notebook document)格式文件。试用了一下Jupyter,该工具其实就是网页界面的编辑器,可以编辑python程序,然后调试。不过感觉在输入的方便性方面不如PyCharm;调试其实也麻烦,需要输入“%run 绝对路径的程序名称”,不如PyCharm直接调试方便了。如果说Jupyter依靠Anaconda强大的科学包,应该Pycharm也是可以安装的。所以还是使用PyCharm为好。
本章介绍了Python的字符串、内建函数、列表、条件判断、循环、嵌套语句、函数、调用模块、文件操作等。代码收录在Python应用实战_01.py。
第2章 网页
要对网页数据抓取,首先需要要熟悉网页的结构和代码,并且要有工具辅助。本章介绍了谷歌浏览器方便的开发调试功能(开发者工具)、URL、HTML、Javascript(id的操作)、Cookie和Session等。
谷歌浏览器的开发者工具的确厉害,可以非常方便的分析网页的结构:更多工具——开发者工具,进入开发者工具后,
可以在右上角选择“Dock side”,即开发窗口的位置(左侧、下侧......);
点击左上角的接头后,可以将鼠标移至网页内任何位置,即可在开发栏中显示对应的源代码;
再把鼠标移回开发栏,右击鼠标,选择“Copy”,就可以拷贝各种内容,特别是直接就可以拷贝XPath的代码了。
不过有些网页做了防范,它们是通过JavaScript的代码来写入数据,XPath其实就“失灵”了。但是不管怎么样,谷歌浏览器方便了开发者,让开发者喜欢用谷歌浏览器给用户开发更多基于谷歌浏览器的产品,自然就有更多的人使用谷歌浏览器了。
第3章 数据抓取
(1)利用request库下载网页,lxml.html转换网页为可分析的对象;(2)通过XPath的语法,可以对lxml.html的对象元素进行定位,并获取数据;(3)通过分析URL的变化规则,对多页的数据进行抓取;(4)对于一些动态的网页,利用谷歌开发者工具分析获取的URL,直接进行数据抓取。
首先介绍了requests库的使用:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36
将用户代理添加到头部信息,就可以“瞒天过海”了:
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
response =requests.get("https://www.zhihu.com",headers=headers)
print(response.text)
另外还介绍了第三方工具库lxml,可以分析html元素及元素属性。在大多数网站域名下有一个文件robots.txt,包含爬虫协议,也叫网络机器人排除协议,就是网站说明可以被抓取的内容和禁止被抓取的内容。
XPath是XML Path Language的缩写,用来查找HTML元素与元素属性。
其表达式:/,选择元素,但必须从HTML的根目录中选择;//,选择所有元素,不管元素在HTML中的位置;.,选择当前元素。如:.//li,选择当前元素下所有的li元素;@,选择HTML元素的属性。如://li[@class]选择所有带有class属性的li元素,//li[@class="fruit"],选择所有class="fruit"的li元素,//div[@attr1="a"][@attr2="b"]选择带有attr1="a"和attr2="b"属性的元素;//element[n],选择所有element元素的第n个元素;//*[@attr="abc"],选择所有带attr="abc"属性的任何元素。
XPath示例
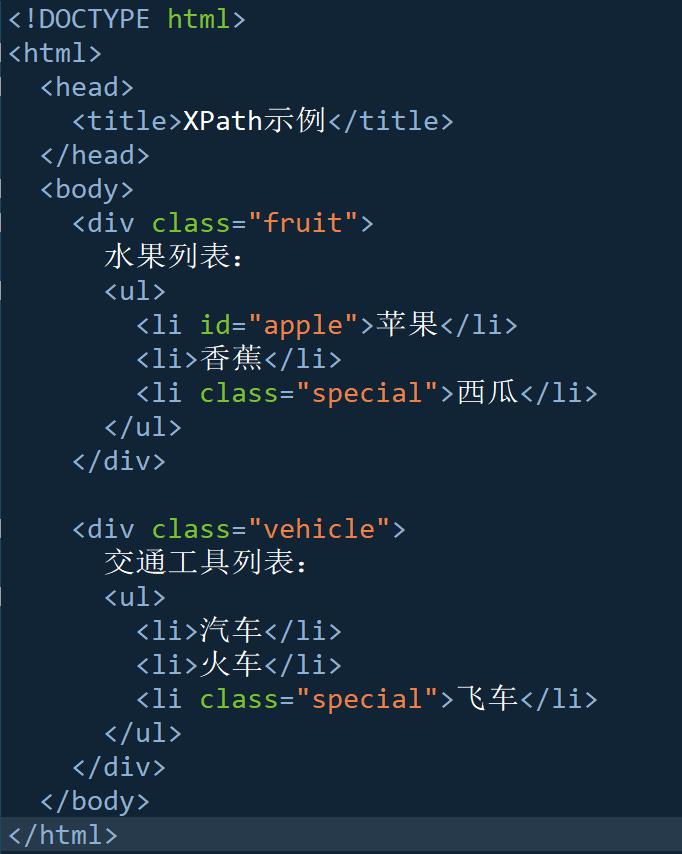
import lxml.html
with open('xpath.html', 'r', encoding='utf-8') as f:
# 通过lxml.html.fromstring()方法
# 将保存在xpath.html中的HTML代码转换成HTML对象
html = lxml.html.fromstring(f.read())
all_div = html.xpath('//div') # 结果是一个列表
print('HTML对象: {}'.format(html))
print('选择所有的元素(2个):', all_div)
print('选择第1个的元素: ', all_div[0]) # 0为第1个
print('选择第1个个内所有的元素: ', all_div[0][0])
print('选择第1个内第1个元素内的第1个的内容: ', all_div[0][0][0].text)
print('选择第1个内第1个元素内的第2个的内容: ', all_div[0][0][1].text)
结果:
HTML对象: Element html at 0x12b1b235c78>
选择所有的元素(2个): [
选择第1个的元素:
选择第1个个内所有的元素:
选择第1个内第1个元素内的第1个的内容: 苹果
选择第1个内第1个元素内的第2个的内容: 香蕉
all_div = html.xpath('//li[@class="special"]')
print('选择所有class="special"的li元素的第2个列表内容:', all_div[1].text)
all_div = html.xpath('//div[@class="fruit"]/ul/li[@class="special"]') # 注意要加上ul
print('选择class="fruit”的div的ul的li(class="special")的内容:', all_div[0].text)
结果:
选择所有class="special"的li元素的第2个列表内容: 飞车
选择class="fruit”的div的ul的li(class="special")的内容: 西瓜 (注意一定要加上ul,按照顺序)
all_div = html.xpath('//div[@class="fruit"]')[0] # 注意要加上ul
all_li = all_div.xpath('.//li') # 在当前选择下再选择
print('在当前选择下再选择:', all_li[0].text)
结果:在当前选择下再选择: 苹果
第4章 文本处理
本章主要介绍正则表达式和Python的re库。书中“4.2 更强的文本工具——Python的re库”。re,应该是模块,module。而“库”应该是library。
文中使用了codecs模块(module),专门用于编码转换,即:coder-decoder。
转义: 表示换行、 表示制表符;
正则表达式:使用元字符匹配(参考)。可以使用re模块中的方法,做:匹配(re.match)、搜索(re.search、re.findall)、替换(re.sub、replace)、去除(strip、split)。strip()方法可以将字符两端不需要的字符去除。
import re
s = " 你好 Python "
new_s = s.strip()
print("{}: |{}|".format("strip()", new_s))
new_s = re.sub('^s+|s+$', '', s)
print("{}: |{}|".format("re.sub()", new_s))
结果:
strip(): |你好 Python|
re.sub(): |你好 Python|
^s+|s+$,这个正则表达式中的元字符“|”的表示:匹配两边的任意一个正则表达式;s 匹配普通空格、制表符、换行符等字符;$,匹配字符串的结尾(^匹配字符串开头)。如果使用s+|s+,即不要(^和$),结果就变成了:re.sub(): |你好Python|。即会将所有的空格都替换。
以下代码是演示findall的使用方法。findall(正则表达式,目标字符串),注意结果是一个列表。
列中的正则表达式“w+”中元字符w是指:匹配组成语言的字符,等价于[a-z]+[0-9]+; +,指:使+前面的正则表达式出现1次或多次。
u4E00-u9FA5是中文的Unicode编码的范围。
import re
s = "肖申克的救赎 /The Shawshank Redemption /月黑高飞(港) / 刺激1995(台)"
chinese = re.findall("w+", s)
# 输出里英文跟数据也被匹配到了
print(chinese)
# 通过中文的unicode范围来进行匹配
chinese = re.findall("[u4E00-u9FA5]+", s)
print(chinese)
# 可以在[ ]元字符里加班一些额外需要匹配的字符
chinese = re.findall("[u4E00-u9FA5()0-9]+", s)
print(chinese)
print(chinese[2])
结果:
['肖申克的救赎', 'The', 'Shawshank', 'Redemption', '月黑高飞', '港', '刺激1995', '台']
['肖申克的救赎', '月黑高飞', '港', '刺激', '台']
['肖申克的救赎', '月黑高飞(港)', '刺激1995(台)']
刺激1995(台)
chinese = re.findall("[u4E00-u9FA50-9()]+", s) # 将数字写在前面,效果一样
获取豆瓣的一周口碑榜
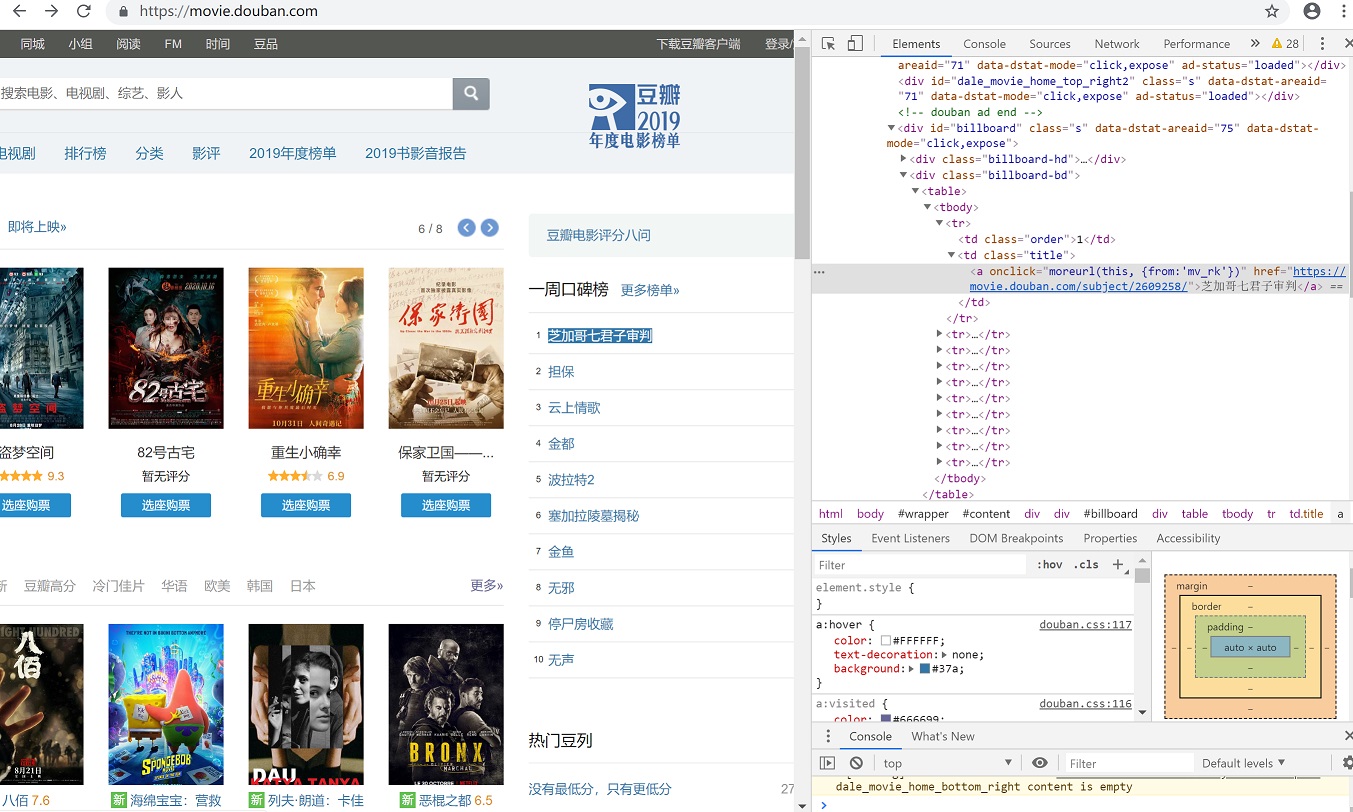
如果用谷歌浏览器直接Copy XPath是://*[@id="billboard"]/div[2]/table/tbody/tr[1]/td[2]/a
因为要循环读取数据,需要将tr[1]改为tr。利用循环,就可以将“一州排行榜”的10条记录读取进来。
import requests
import lxml.html
myheaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"}
# 获取豆瓣电影首页
http_response = requests.get('https://movie.douban.com', headers=myheaders)
# 设置中文编码
http_response.encoding = 'utf-8'
html = lxml.html.fromstring(http_response.text)
# 通过xpath来获取所有电影
titles = html.xpath('//*[@id="billboard"]/div[2]/table/tr/td[2]/a')
for title in titles:
print(title.text_content())
获取豆瓣 TOP 250的网页
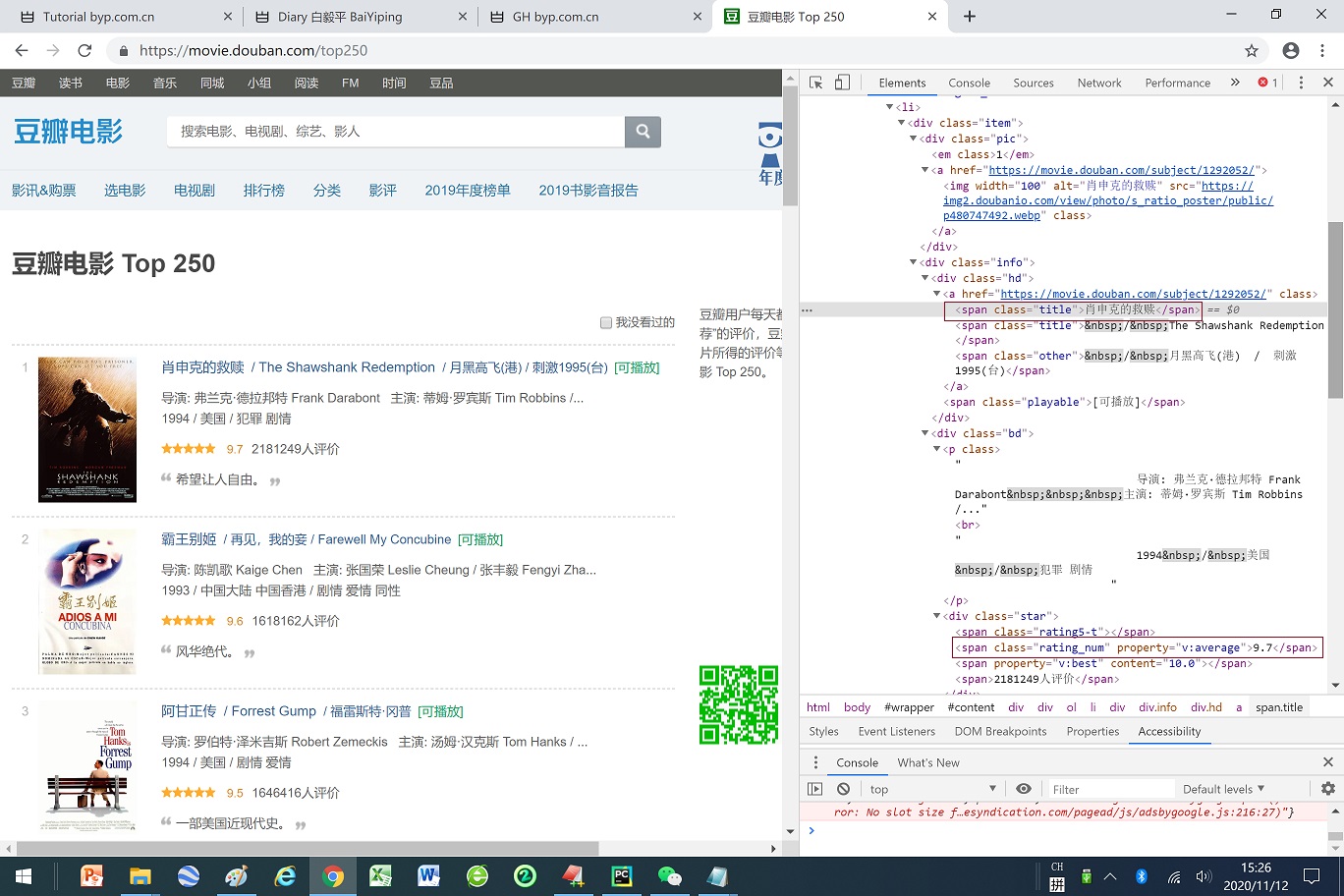
import requests
import lxml.html
myheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"}
# 获取豆瓣电影Top250的网页,
# 并转换了可使用XPath分析的对象
http_response = requests.get('https://movie.douban.com/top250', headers=myheaders)
http_response.encoding = 'utf-8'
html = lxml.html.fromstring(http_response.text)
# 获取所有电影列表的
结果:
<<肖申克的救赎>> - 9.7
......
第5章 数据分析
主要介绍Pandas、Numpy、matplotlib:了解Numpy生成数据的方法;学习Pandas的两个核心数据结构:Series和DataFrame;运用Series和DataFrame来进行数据分析;学习用Pandas和matplotlib来进行可视化。
numpy.org的quickstart,
Pandas是基于Numpy的一种工具,相当于Python中的Excel,最初是作为金融数据分析工具开发出来的。Pandas其实和大熊猫panda没什么关系,它的来源是panel data(面板数据)和data analysis(数据分析)。Pandas有两种数据结构:Series(一种带有标签index的一维数组)和DataFrame(二维数组接近Excel)。
import calendar
import numpy as np
import pandas as pd
index = [calendar.month_abbr[i] for i in range(1, 13)]
data = np.random.uniform(10, 100, (12, 3)) # 生成10-100范围内的随机数,并组成12行3列的数组
# 如果生成整数的随机数用np.random.randint()
report = pd.DataFrame(data, index=index, columns=["2016", "2017", "2018"])
# print(report)
report.to_csv("report.csv")
re = pd.read_csv("report.csv", index_col=0)
print(re)
结果:(并写入report.csv文件内)
2016 2017 2018
Jan 44.237134 32.126186 86.549166
Feb 92.672201 56.990872 72.266689
Mar 28.130815 70.833730 90.555162
Apr 53.577553 56.770754 55.499232
May 70.540372 59.360135 51.425764
Jun 52.146123 43.503287 50.584118
Jul 42.569049 83.296186 19.361965
Aug 59.140954 74.326325 13.838346
Sep 42.306816 48.470818 69.012636
Oct 78.358746 47.332387 24.429059
Nov 99.277085 86.317648 37.762936
Dec 42.531059 34.329408 61.622437
参考网站:
https://www.python.org/
https://requests.readthedocs.io
https://developer.mozilla.org/en-US/docs/Web/HTML
https://matplotlib.org