XGBoost
XGBoost

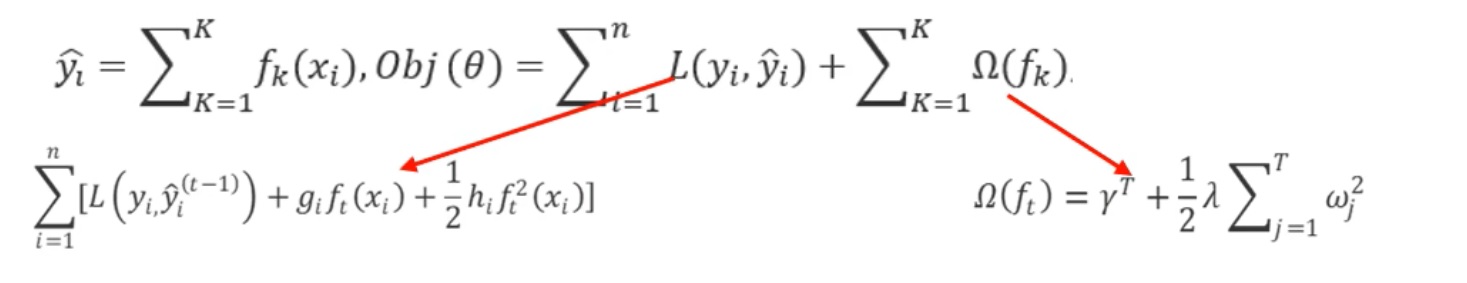
损失函数做二阶泰勒展开。
2、算法计算效率的优化:可以并行计算。对每个弱学习器,如决策树建立的过程做并行选择,找到合适的子树节点分裂特征和特征值,从而提升运行效率。
XGBoost调参策略
1、选择一组初始参数;2、改变max_depth和min_child_weight;3、调节gamma降低模型过拟合风险;4、调节subsample和colsample_bytree改变数据采样策略;5、调节学习率eta。
很多概念其实都是源自英语世界,因此需要对其英文名字含义要有一定的了解。boost,根据牛津词典,动词的意思是“to make sth increase, or become better or more successful”,可理解为“使增长、变好或加强”;名词意思就是增长提高(an increase in sth)。动词如果加上“ing”成名词。在算法中用到的boost,其实都是boosting的缩写。
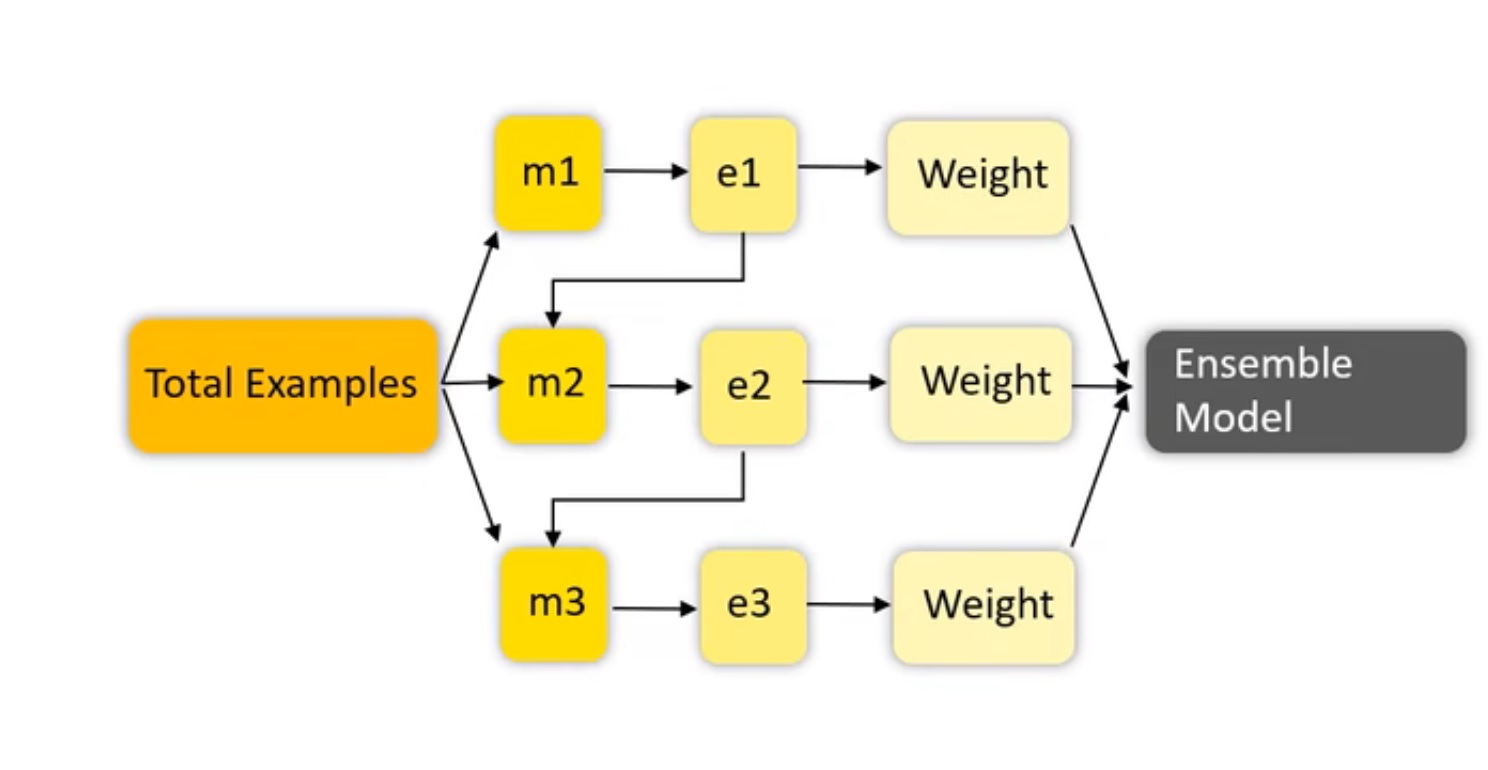
机器学习中的Boosting是一种集成学习方法(Ensemble Learning)。集成学习,是通过结合几个模型的元算法(meta-algorithm)的方法。集成学习有三种模式:bagging、boosting、stacking。
GBDT有三大主流“神器”:CatBoost、XGBoost、LightGBM,都是在GBDT算法框架下的一种改进实现。三大神器各有特点:XGBoost被广泛的应用于工业界,LightGBM有效的提升了GBDT的计算效率,而CatBoost(俄罗斯的搜索巨头Yandex于2017年开源的机器学习库)号称是比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。
例如,Adaboost=Adaptive Boosting(自适应增强,[Yoav Freund and Robert Schapire , 1995])、GBDT=Gradient Boosting Decision Tree(梯度增强决策树)、XGBoost=eXtreme Gradient Boosting(极致梯度增强或提升)。
XGBoost的基本思路和GBDT相同,但是做了一些优化:二阶导数使损失函数更精确;正则项避免树过拟合;Block存储可以并行计算等。因而,具有高效、灵活、轻便的特点。
GBDT,Gradient Boosting Decision Tree,一种基于决策树的集成算法(a powerful machine learning algorithm)。其中Gradient Boosting是集成方法boosting中的一种算法,通过梯度下降来对新的学习器进行迭代。而GBDT中采用的就是CART决策树。 Boosting指把多个弱学习器相加,产生一个新的强学习器。经典例子有:adboost、GBDT、XGBoost等(来源)
A Gentle Introduction to Gradient Boosting (来源|L)
XGBoost是华盛顿大学计算机系博士生陈天奇(知乎)开发(论文|L)。
Pima Indians数据集
本章使用Pina Indians糖尿病发病情况数据集。这是一个可从 UCI Machine Lermning免费下载的标准机器学习数据集( hp:rcihv/ic uci eruldaatsrsma+ndiatDiabetes )。它描述了Pima Indians 的患者医疗记录数据,以及他们是否在五年内发生糖尿病。这是一个二元分类问题(糖尿病为1或非糖尿病为0),描述每个患者的输入变量是数值类型,具有不同的尺度。下面列出 了数据集的8个属性和输出结果。
(1) Number of times pregnant: 怀孕次数。
(2) Plasma glucose concentration a 2 hours in an oral glucose tolerance test: 2小时口服葡萄糖耐量试验中血浆葡萄糖浓度。
(3) Diastolic blood pressure (mm Hg):舒张压。
(4) Triceps skin fold thickness (mm):三头肌皮褶皱厚度。
(5) 2-hour serum insulin (mu U/ml): 2小时血清胰岛素。
(6) Body mass index (weight in kg(heignt in m^2):身体质量指数。
(7) Diabes pedigree fnction:糖尿病谱系功能。
(8) Age (years):年龄。
(9) Class variable (0 or 1):是否是糖尿病。
Indians.py | pima-indians-diabetes.csv | Indians_plot_feature_importance.py
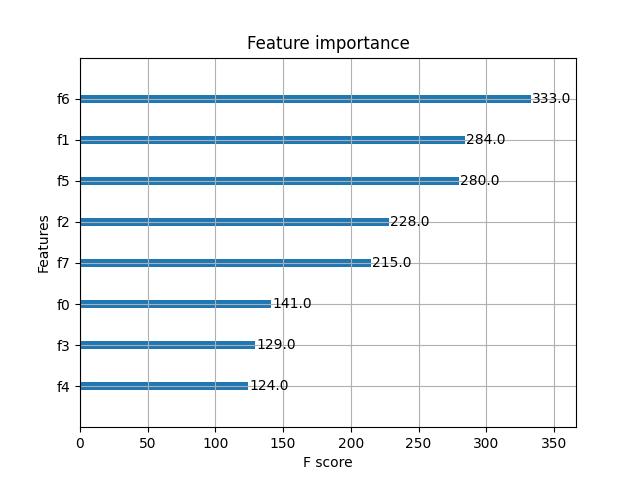
Feature importance
参数
1. learning rate
2. tree: max_depth, min_child_weight, subsample, colsample_bytree, gamma
3. 正则化参数: lambda, alpha
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=12343)
# 训练模型
model = xgb.XGBClassifier(max_depth=5,learning_rate=0.1,n_estimators=160,silent=True,objective='multi:softmax')
model.fit(X_train,y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
#计算准确率
accuracy = accuracy_score(y_test,y_pred)
print('accuracy:%2.f%%'%(accuracy*100))
# 显示重要特征
plot_importance(model)
plt.show()
参考资料:
官方文档
learn中的XGBClassifier参数详解
XGBoost实战演示
数据挖掘领域十大经典算法之—AdaBoost算法(超详细附代码)
GBDT算法介绍
大白话解释模型产生过拟合的原因!
泛化能力 六花花花你可以的
XGBoost模型调参、训练、保存、评估和预测
XGBoost的调用、参数调优、模型保存、模型显示、预测评价全套
XGBoost——机器学习(理论+图解+安装方法+python代码)
Xgboost的使用及参数详解
XGBoost的两种使用方式
XGBoost参数调优完全指南(附Python代码)
xgboost调参
XGBoost使用教程(纯xgboost方法)
GBDT的原理、公式推导、Python实现、可视化和应用
XGBoost安装(加州大学尔湾分校)