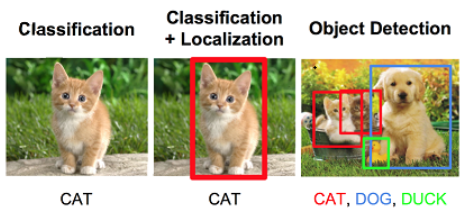
计算机视觉
计算机视觉
YOLO |
实例分割=目标检测+语义分割
目标检测,给你一张有一条狗的图片,输入训练好的模型中(假设模型包含了所有类型的狗),不管狗出现在图片中的哪个位置,它都能被检测为狗;给你一张有两条狗的图片,输入网络,会生成两个bbox,均被检测为狗,无法进行个体的区分;
语义分割:对所有像素进行分类,图片中只要出现狗,都会被分为一类,同样无法进行个体的区分;
实例分割:在所有不同类的狗的像素都被分类为狗的基础上,对不同类的狗进行目标定位,再给狗1和狗2的标签,这就是实例分割。
在计算机视觉的基本任务中目标检测是预测图像中目标位置和类别。语义分割则是在像素级别上对目标分类。而实例分割可看作目标检测和语义分割结合体,旨在检测图像中所有目标实例,并针对每个实例标记属于该类别的像素。即不仅需要对不同类别目标进行像素级别分割,还要对不同目标进行区分。与其他计算机视觉研究问题相比,实例分割的挑战性在于:
1) 需要预测并区分图像中每个目标的位置和语义掩码,并且由于实例的不可知形状使得预测实例分割的掩码比目标检测任务预测矩形边界框更灵活;
2) 密集目标的相互遮挡与重叠使网络很难有效区分不同实例,并且小目标的实例分割由于普遍缺少细节导致分割精度仍然很低;
3) 繁琐精细的数据标注耗费大量人力与时间,如何减少成本,有效利用现有未标注或粗糙标注的数据提升实例分割精度仍是一个亟待解决的问题。
苏丽,孙雨鑫,苑守正.基于深度学习的实例分割研究综述[J].智能系统学报,2022,17(1):16-31.
目标检测概念
图像识别解决“是什么”的问题,目标检测解决了“在哪里”的问题。简单来说,在图像识别的基础上,以包围盒(bbox)的形式把物体框出来。
目标检测,Object Detection,也叫目标提取,是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。
1、Ground Truth
Ground Truth(GT)代表通过人工等方式为数据赋予的真实标签,用于训练模型和验证、测试模型性能。
2、Bounding Box
目标检测需要定位图像中的目标位置和类别,反映在数据上的形式就是使用矩形框框出目标区域,并标记类别标签,这就是目标检测的Bounding Box (bbox),标注与算法输出都使用该形式,以便机器学习并对比实验结果。一般一般表示为(xmin, ymin, xmax, ymax)。(xmin, ymin)为bbox左下角的坐标,(xmax, ymax)为右上角的坐标(介绍)。

3、gtbox(真实框) gtbox(ground truth box)是人工标注的框,存放在标注文件中。
4、pbox(预测框) pbox(prediction box)是由目标检测模型计算输出的框。
5、NMS(非极大值抑制)
目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。

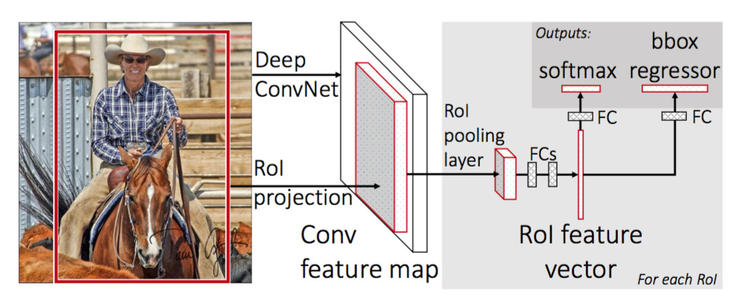
6、Region of Interest
Region of Interest(ROI)兴趣关注区域,与bbox概念类似,定义图像中感谢的部分,交给机器进行学习。
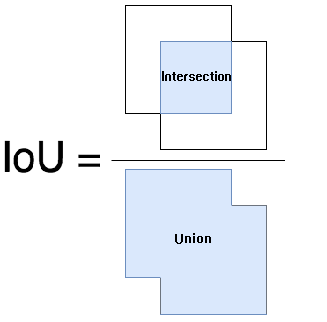
7、Intersection over Union
Intersection over Union(IoU),交集并集比(交并比)。IoU(Intersection over Union)表示预测框(candidate bound)与真实框(ground truth bound)之间的重叠程度,也就是它们的交集与并集的面积比,计算公式为:IOU=(A∩B)/(A∪B)。IOU越大,说明两个边框重合度越高。最理想情况是完全重叠,即比值为1。。
8、Confidence
Confidence,置信度,表面检测模型对于自己检测出目标的置信程度,值越大表明模型更加笃定自己检测结果的准确性。
目标检测常用的数据集
目标检测常用的数据集包括PASCAL VOC、ImageNet、MS COCO等,这些数据集用于研究者测试算法性能或者用于竞赛。
1、PASCAL VOC
PASCAL VOC是目标检测、分类、分割等领域一个有名的数据集。从2005到2012年,共举办了8个不同的挑战赛。PASCAL VOC包含约10,000张带有边界框的图片用于训练和验证。但是,PASCAL VOC数据集仅包含20个类别,因此其被看成目标检测问题的一个基准数据集。

2、ImageNet
ImageNet在2013年放出了包含边界框的目标检测数据集。训练数据集包含500,000张图片,属于200类物体。由于数据集太大,训练所需计算量很大,因而很少使用。同时,由于类别数也比较多,目标检测的难度也相当大。
3、MS COCO
COCO(Common Objects in Context)是一个新的图像识别、分割和图像语义数据集,由微软赞助,图像中不仅有标注类别、位置信息,还有对图像的语义文本描述。
目标检测的评估指标
1、mAP(检测精度指标)
首先需要介绍P-R曲线,它是以精度(precision)和召回率(recall)作为纵、横轴坐标,通过选取不同阈值时对应的精度和召回率画出的二维曲线。一般来说,精度越高,召回越低,反之亦然。

P-R曲线围起来的面积被叫作AP值(Average Precision,平均精度),通常来说一个越好的分类器,AP值越高。
在目标检测中,每一类物体都可以根据精度和召回率绘制出该类的P-R曲线,得到检测该类的AP值,把检测各类物体的AP值取平均可以得到一个新的指标mAP(Mean Average Precision)。我们一般把mAP作为目标检测中衡量检测精度的指标。
2、FPS(检测速度指标)
只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。当然。另外也可以使用处理一张图片所需时间来评估检测速度,时间越短,速度越快。
检测判定
在分类任务中,分类模型输出的结果作为其分类的类别,将该输出与真实类别标签比较即可确定此次预测是否正确,相应地得可以将此次预测划定到TP、FP、TN、FN中。
而目标检测任务中的输出结果不同于分类,该结果 包含了图像中某位置属于某类别的信息,而且很可能包含多个目标,而事实上,输出结果与标注标签完全一致是不现实的,那么如何判定检测结果是否正确呢。
在目标检测中判定结果正确需要预先设定IoU阈值,然后逐个类别判定检测框:
·遍历每个类别
·将该类别的预测框按confidence降序排列
·对于每个预测bbox,找出与其有最大IoU的gt_bbox
·如果该gt_bbox之前没有被分配且IoU大于给定的阈值(比如0.5),那将该gt_bbox分配该给预测bbox,设置该预测bbox为TP;否则设置该预测bbox为FP
·没有被正确预测到的gt_bbox设置为FN
·在检测结果中没有显式的TN
性能评估
判定出结果后就可以用分类的评价体系计算性能指标了:
机器学习-基础知识 - Precision, Recall, Sensitivity, Specificity, Accuracy, FNR, FPR, TPR, TNR, F1 Score, Balanced F Score
也可以绘制ROC、PR曲线:
机器学习-基础知识 - PR、ROC曲线与AUC
参考资料:1|2
图像分类、目标检测、语义分割、实例分割等计算机视觉方向基本概念