AI
人工智能(Artificial Intelligence)
AI | ML | DL
Algorithm | Datasets | Computability
大赛 | 大会 | 大神 | 高校/研究机构 | 学会 | 论文 | App | 行业 |
研究领域
计算机视觉 | 智能预报 | LLMs | 算力 | 排名测评 | RAG | 向量数据库 | Agent |
Transformer
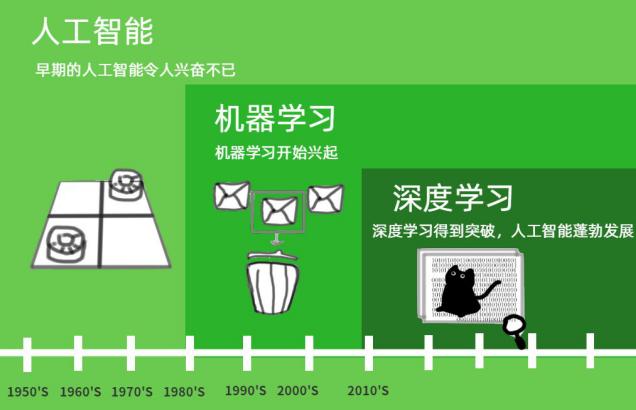
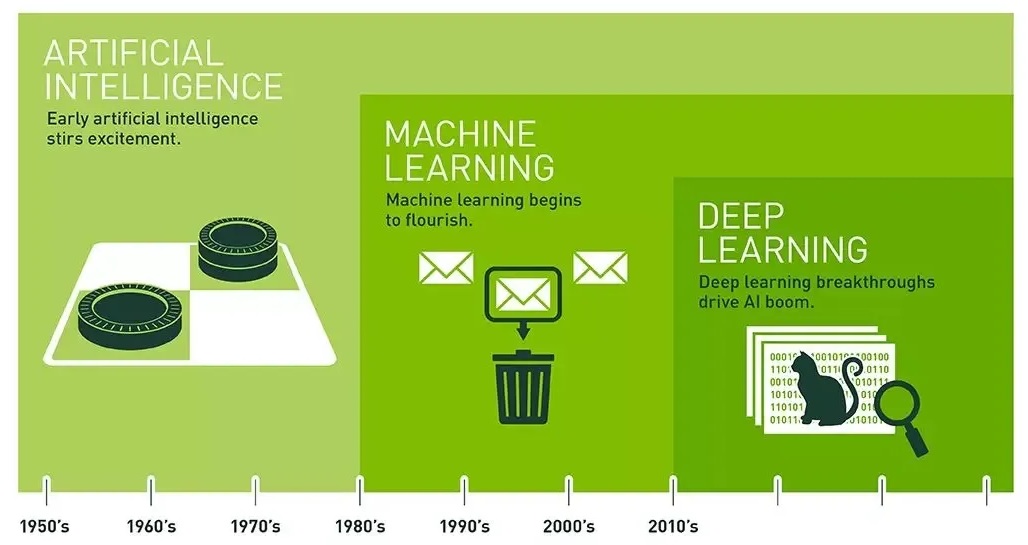
AI Winter : History| 三起二落 | 七个片段 | NLP反思
2022年3月,Robust.AI创始人Gary Marcus发表《深度学习撞墙了》(Deep Learning is Hitting a Wall),认为纯粹的端到端深度学习差不多走到了尽头,整个AI领域必须要寻找新出路。Hinton和LeCun对他的观点发出了驳斥。LeCun认为,深度学习并没有撞墙,但的确有一些障碍需要清除。
2022年11月9日,在联想Tech World大会上,李彦宏提出了人工智能出现“方向性的改变”:“无论是在技术层面还是在商业应用层面,人工智能都有了巨大的进展,有些甚至时方向性的改变”。(该观点他在2022的WAIC世界人工智能大会上同样表达)。他所指的“方向性改变”是:“AI从理解语言、理解文字、理解图片和视频,走向了生成内容。我们称之为AIGC,AI generated content,即人工智能自动生成内容”。2022年两会期间,依托百度AIGC技术的数字主播度晓晓正式上岗。2022年,度晓晓挑战高考作文,在40秒内写出了40篇,专家评阅,其得分可以在总考生前25%。
除了自动驾驶,2021年以来百度在人工智能领域商业化进展,最明显的是基础设施的智能化改造:智能交通、能源水利基础设施智能化,工业互联网领域(“开物”平台)。基于压强式、马拉松式的技术研发投入,百度发展出了三大增长引擎,以智能云为代表的新兴业务、以智能驾驶和小度为代表的前沿业务。根据2021年6月IDC报告,百度深度学习平台(飞浆)成为中国使用最广泛的平台,超过了Google的TensorFlow和META的PyTorch。
ILSVRC停办的那一年,诞生了Transformer架构,被人认为“2010年代十年中最伟大的发明”,它让更为高效的“多头注意力机制”技术路线,取代了之前的卷积神经网络,成为更优秀的AI解法。Transformer诞生后,谷歌出了架构Vision Transformer(ViT),OpenAI发布了DALL·E-2,DeepMind发布了AlphaCode。
2021-2022年,震动科技界的优秀论文(MLP-Mixer,2021)宣称卷积神经网络和注意力之外,还有其它的AI进阶实现路线;香港中文大学论文提出,Transformer可以与GAN(生成对抗网络)结合实现AI效率倍增。

2022年8月美国科罗拉多州举办艺术博览会,一幅名为《太空歌剧院》的画作最终获得数字艺术类别冠军。该作品作者为39岁游戏设计师Jason Allen,先由AI制图工具Midjourney(输入文字描述生成图片的工具)生成,再经Photoshop润色而來。
《经济学人》2022年6月刊的一篇文章'AI’s new frontier'(B站|知乎)。Handled well, it is more likely to complement humanity than usurp it.
机器学习应用领域:传统预测(量化投资、销量预测、天气预报等)、图像识别(人脸识别、物件识别、无人驾驶等)、自然语言处理(语言翻译、文本分类、情感分析、自动聊天等)。
机器学习:从数据中自动分析获得模型,并利用模型对未知数据进行预测。
调参:机器学习模型中有两类参数:(1)模型参数(Parameter)。模型本身的参数。例如,线性回归直线的加权系数(斜率)及其偏差项(截距);(2)超算数(Hyperparameter)。调优参数(tuning parameters),需要人为设定。例如,正则化系数、决策树模型中的树的深度等。
模型调参:网格搜索(GridSearchCV)与随机搜索(RandomizedSearchCV)
1、网格搜索。在我们不能确定超参数的时候,需要通过不断验证超参数,来确定最优的参数值。这个过程就是不断搜索最优的参数值。这个过程称为网格搜索;
2、检查验证。将准备好的训练数据进行拆分,分为训练集和验证集。训练集和验证集可以通过手动设置,过程如下:
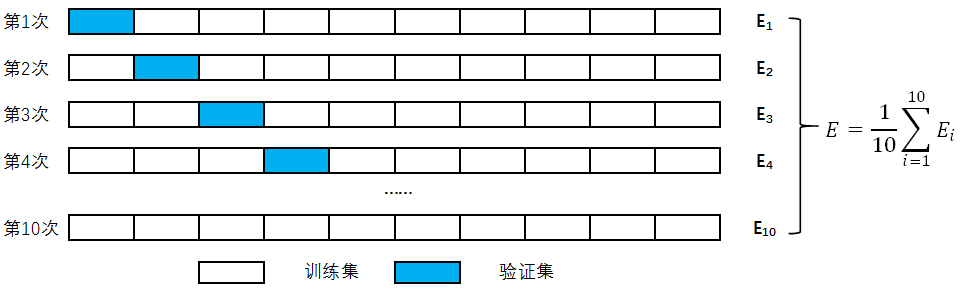
示例程序:KNN03
网格搜索(和交叉验证)(GridSearchCV),即GridSearch+CV。网格搜索,在指定参数范围内,按照一定步长调整(搜索)参数,利用调整的参数训练学习器,从所有的参数中在验证集上精度最高的参数,是一个训练和比较的过程。缺点是耗时,因此网格搜索适合于三四个(或者更少)的超参数。
机器学习与深度学习的区别:例如要识别照片里面的猫。
如果用机器学习来做,需要给它一张照片,除了告知里面有猫,还要告知猫的特征,让它学习识别;
如果用深度学习来做,只需要给它一张照片,只是告知里面有猫,而不需要告知猫的特征,它自己会去找特征,并且识别。
机器学习算法分类:
监督学习:数据不连续就用分类(方法)、数据连续就用回归(方法),数据数据有特征有标签,即有标准答案;
无监督学习:输入数据有特征无标签,即无标准答案;
有监督学习:KNN(K近邻)算法、RF(随机森林)算法、GBDT算法(XGBoost)、LightGBM、CatBoost、神经网络(CNN、TCN等)
无监督学习:聚类算法(K-Means)、DBSCAN,数据降维(PCA,也就是我们常用的EOF)、EM算法、GMM算法
强化学习:GAN对抗生成网络
大数据技术:Spark计算框架,Spark机器学习MLlib和ML模块
概率图模型算法:贝叶斯分类、HMM算法、最大熵模型、CRF算法
深度学习:神经网络算法、BP反向传播算法、TensorFlow深度学习工具
图像识别:卷积神经网络(LeNet,AlexNet,VGG16,InceptionV3,ResNet,DenseNet,MobileNet,GAN生成对抗网络)、OpenCV模块、古典目标检测算法、现代目标检测算法
自然语言:词向量与词嵌入、循环神经网络原理与优化、Transformer 和Bert
应用:
图像识别项目:电缆缺陷检测、电子元件缺陷检测、安全帽检测、人脸识别
自然语言处理项目:OCR识别、实体关系抽取、自动聊天机器人、知识图谱
数据挖掘:推荐系统、智能商业分析
最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
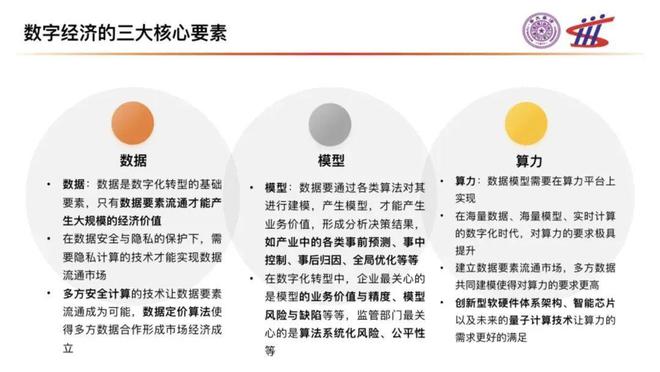
央企数字化研究院首席科学家姚期智作了《数字经济领域的核心技术》的主题演讲
机器学习一般的数据集会划分为两部分:
训练数据:用于训练,构建模型,70%、80%、75%;
测试数据:在模型检验时使用,用于评估模型是否有效,30%、20%、30%
特征工程
pandas:数据读取非常方便以及基本的处理格式的工具;
sklearn:对于特征的处理提供了强大的接口;
特征工程包含内容:(1)特征抽取、(2)特征预处理、(3)特征降维;
字典特征提取:类别之间公平,将类别转换为one-hot编码,几个类别就占几个位置。对于特征当中存在的类别信息进行one-hot编码处理
特征工程 第一步 特征提取;第二部特征预处理;第三步 特征降维
特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。无量纲化:归一化、标准化。
异常值:(1)对一归一化来说,如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变;(2)对于标准化来说:如果出现异常值,由于具有一定的数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。一般应用场景为在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
降维:降低随机变量(特征)的个数,得到一组“不相关”主变量的过程。降维的两种方式:特征选择和主成分分析(可以理解为一种特征提取的方法)。
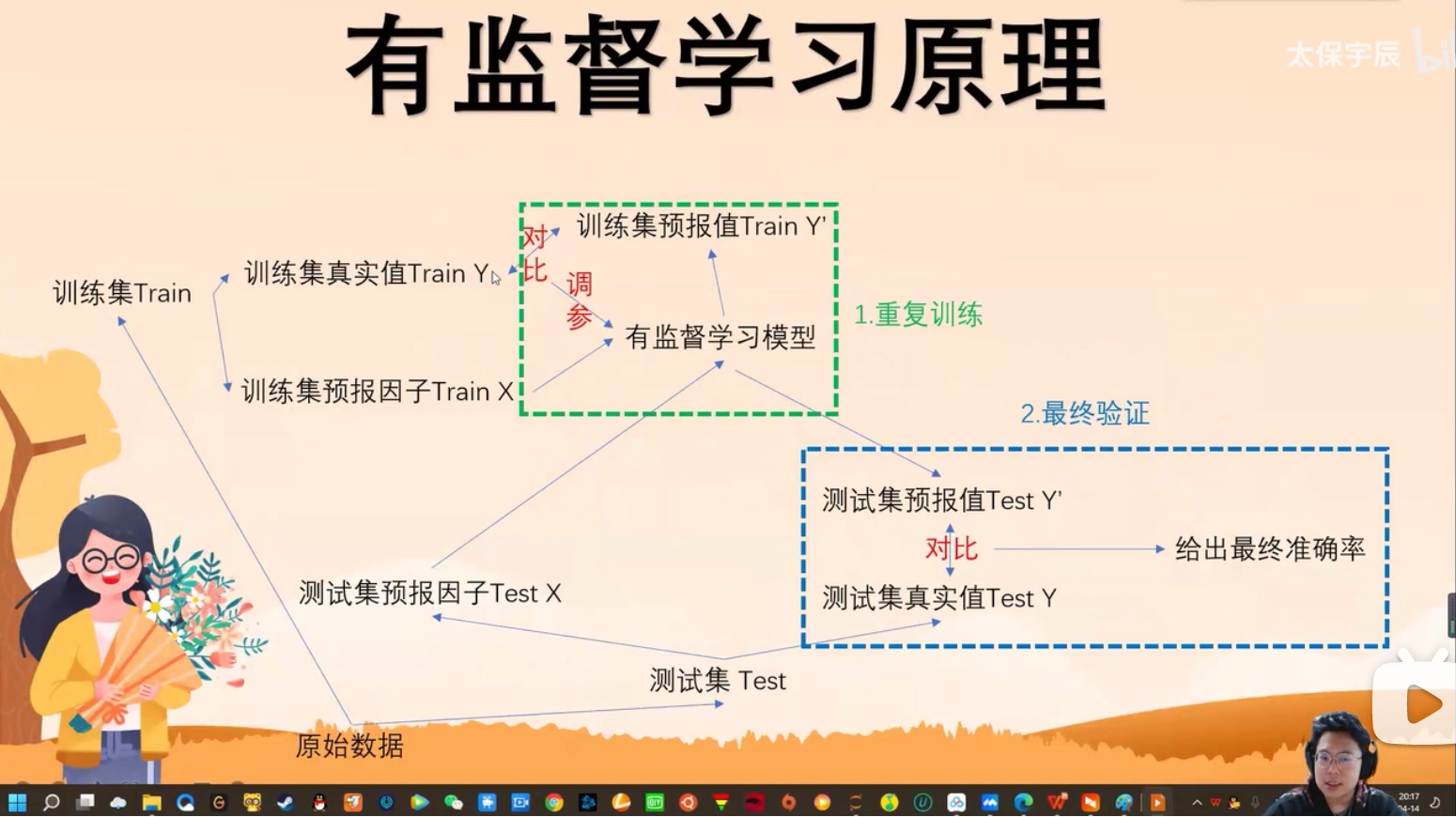
有监督学习原理
决策树算法
1、随机森林(RF, Breimen L,2001): 被证明不出众(Sahin etal,2020)
2、梯度提升决策树:
(1)Catboost (Dorogush A V etal., 2018)
(2)LightGBM (Meng Q, 2018):被证明更优(Essam Al Daoud, 2019)
(3)XGBoost (Chen T etal.,2016)


如何解决GBDT的过拟合/欠拟合问题?
决策树越复杂,越容易过拟合;反之决策树越简单,越容易欠拟合。调参主要是以下几个参数:
learning_rate:学习速率。越小越容易过拟合,越大越容易欠拟合;
num_leaves:最大叶子节点数。越大越容易过拟合,越小越容易欠拟合;
max_depth:最大树深度。越深越容易过拟合,越浅越容易欠拟合;
min_child_sample:每个叶子节点上的最小样本数。越小越容易过拟合,越多越容易欠拟合。
Deep learning for multi-year ENSO forecasts (Nature | 知乎 | 收录)
非常详细的sklearn介绍
黑马程序员3天快速入门python机器学习
鸢尾花种类预测
风云论坛159期---Python机器学习原理及在气象中的应用
【机器学习】决策树(下)——XGBoost、LightGBM(非常详细)
肝疯了!2022最新保姆级人工智能学习路线!你只需要看这一篇!
床长人工智能教程
机器学习之有监督学习
集成学习之bagging,stacking,boosting
Python之网格搜索与检查验证-5.2
Python机器学习:GridSearchCV和RandomizedSearchCV
什么是深度学习?
2万字解读:人工智能这次真的能带动科技产业复苏么?